Vite
vite 与 webpack - 区别
侧重点不同
vite 侧重于浏览器端开发体验, 而webpack侧重于兼容性(webpack将代码打包好后可在浏览器或服务器运行JS代码)
webpack支持多模块化(CommonJS、ES6 Modules),而vite是基于ES6 Modules(只允许打包后在代码中使用 ES6 Modules 模块语法,即决定了其只能优化浏览器端的开发体验)
PS:目前Node最新版本也支持了 ES6 Modules 语法
打包流程
由于webpack支持多模块化,打包开始必须首先统一模块化代码,所以意味着在启动开发服务器前它需要将所有依赖全部读一遍,这才导致了启动速度要低于vite
vite是首先启动开发服务器,找到配置文件中的入口(index.js),进行路由导航后,根据导航的页面不同,从而按需加载依赖
create-vite 和 vite - 区别?
create-yarn create vite后的事情:
先全局安装 create-vite 脚手架
直接运行 create-vite bin目录下的一个执行配置
从而创建一个 vite 项目 (Vue、React.....)
create-vie 与 vite - 关系
create-vite 内置了 vite
create-vie || vue-cli 提供预设
构建预设好的初始项目工程
脚手架已经帮用户将项目配置调整到最佳实践
依赖预构建
在打包依赖引入时,vite会开启自动补全路径
vite找到对应依赖,然后调用 esbuild(对js语法处理的一个库)将其他规范转换为 es module 规范
转换好的依赖代码放到当前目录下的 node_modules/.vite/deps,同时对 es module 规范的各个模块进行统一集成
解决了如下问题:
方便了自动补全依赖路径的重写
统一了依赖的 ES6 Module 规范
解决网络多包传输性能问题 (PS:由于一个依赖里也可能依赖其他依赖,vite会将这个依赖图中的所有依赖集成到一个模块或几个模块中,统一进行返回)(简单点解释就是根据import进行替换植入 )
开发/生产环境 and 环境变量处理
在 Vite 中,loadEnv 函数用于加载环境变量,它依赖于 dotenv 第三方库。这个函数可以帮助你在 Vite 配置文件中根据当前的工作目录和模式(mode)来加载相应的 .env 文件。这些环境变量可以用于配置你的应用。
const env = loadenv( mode, envDir: process.cwd( ), prefixes: "" ) 会发生如下事情:
dotenv会自动读取 process.cwd( ) 目录下的 .env 文件,并解析文件中的对应的环境变量,并将其注入到对象中
而当 yarn dev --mode (ModeName)时,此时寻找 process.cwd( ) 目录下的 .env.[ ModeName ] 文件,解析得到另外的环境变量,并放进对象
解析顺序为 .env -> .env.mode_name -> ... ,并且会进行重名覆盖
.env 文件中的环境变量是开发/生产共有的。
vite会在客户端将环境变量注入到 import.meta.env 中,但只会将有规定前缀的变量进行解析注入(比如 VITE_ENV=111 )
【原理篇】vite如何教浏览器识别单文件
vite会自动地在后台启动开发服务器处理请求
浏览器通过url去请求资源(html、js、.vue....),例如 vue 项目会通过入口 index.html 再请求 main.js (当然,浏览器不会没完没了的请求,vite会进行依赖预构建)
每次请求不同的资源时,请求 .js 则返回 .js,请求 .html 则返回 .html,而当请求到 .vue 这种浏览器不认识的代码时,则会先交由vite进行”编译“/”字符串替换“转为 js 代码再返回给浏览器
vite”编译“/”字符串替换“ 单文件可以粗略的理解为:以vue为例,Vite 会使用 @vue/compiler-sfc 包来解析和编译该文件(将Vue SFC 组件编译为 JavaScript),编译后的 JavaScript 代码会被模块化(scripts、css、template...),在开发服务器上,Vite 会将编译后的模块作为服务端渲染的结果返回给浏览器,浏览器可以直接执行此 JavaScript 代码,从而在客户端渲染出 Vue 组件
后端通过设置响应头的 “Content-Type” : “text/html" / "text/javascript"...告诉浏览器以什么方式解析该返回的文件
CSS以及CSS模块化
vite天生就支持对css文件的直接处理
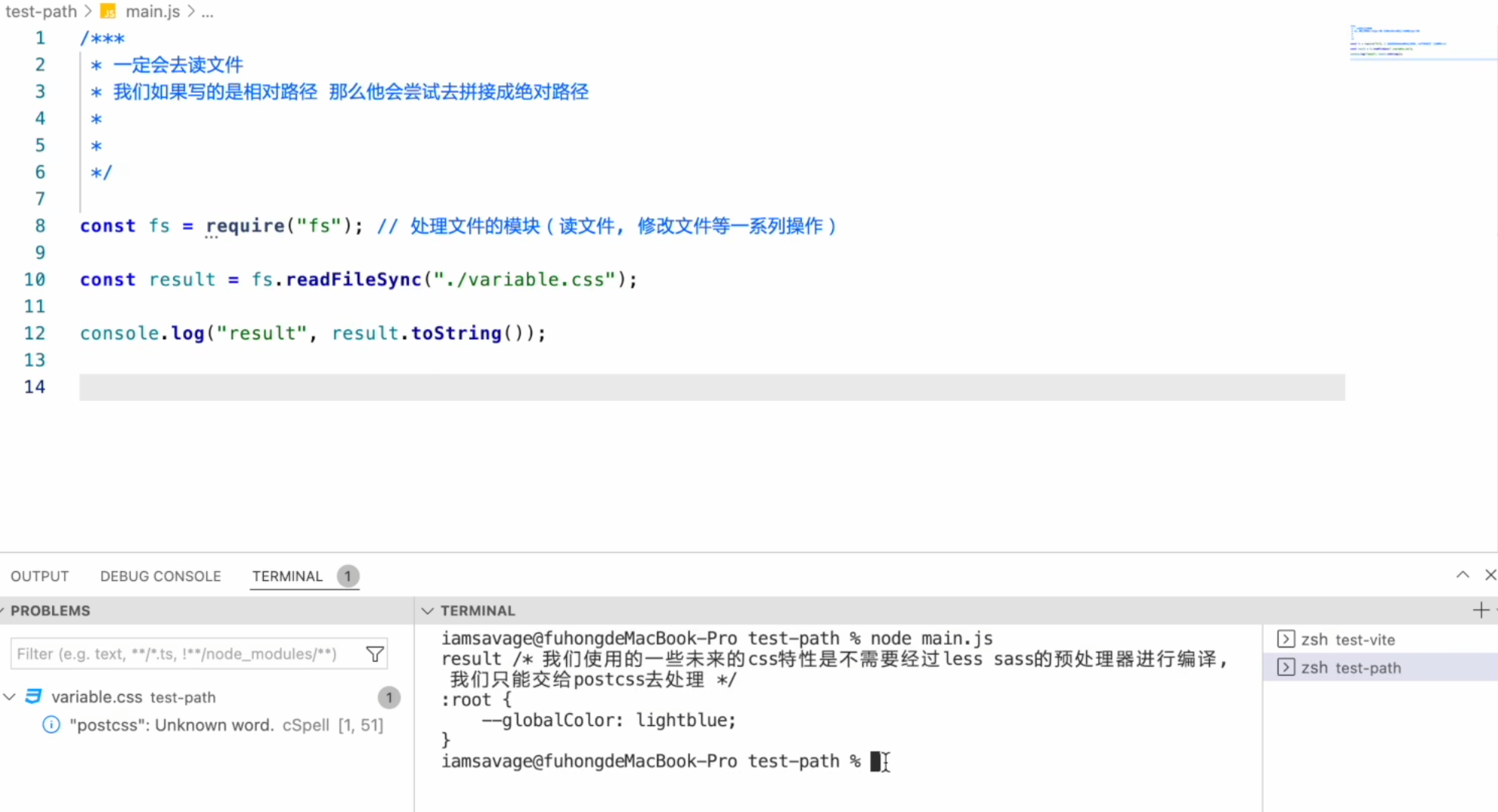
vite读取到 main.js 中引用了 xxx.css
直接使用 fs 模块去读取 css文件内容
直接创建style标签,将读取到的样式插入到style标签中
将<style></style> 插入到 index.html 的 head 中(如图)
再将原css文件中的内容替换为 js脚本(如何解析以Content-Type为准,方便热更新或者css模块化,如图)


css模块化 - 解决协同开发下的命名冲突问题
css模块化解读(基于node):
请求样式文件时,node会接受并去读取css文件,当碰到 .module.css 结尾的文件时,则开启css模块化(module是一种约定)
开启后,将所有样式选择器名称进行一定规则的替换(例如 container -> container_2itt1)
同时创建映射对象 { container : ”container_2itt1“ }
将替换后的内容插入到 index.html 的 head 中 (说明node也读取到了index.html中的内容,将读取到的样式插入其中)
将 .module.css 原文件内容全部抹除,替换为 js脚本
将创建的映射对象在脚本中默认导出


css模块化 -vite配置文件中css配置流程(modules)
配置项modules:对css正常模块化的行为进行覆盖
modules 配置最终会丢到 postcss 去处理
(都不太常用,vite都按照最佳实践配置好了)
localConvention:修改生成的配置对象的Key的展示形式(驼峰还是中划线)
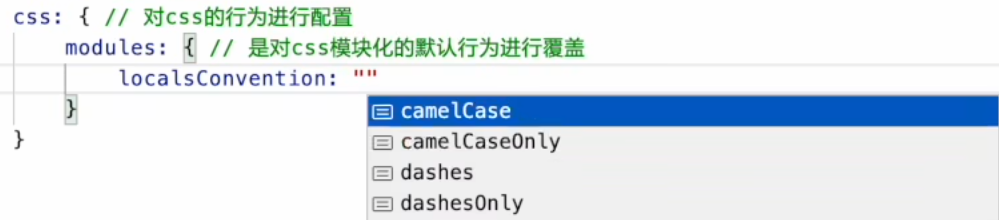
scopeBehaviour:“local"/"global"(开启/关闭css模块化)
generateScopedName:”[name]_[local]_[hash:5]" 控制模块化类名的生成规范
hashPrefix:{String} 由于生成hash值时会根据类名 + 一些随机字符串的拼接结果进行生成,规定这个属性后,最后生成的hash值就会根据 类名 + hashPrefix + 一些随机字符串的拼接结果进行生成,很鸡肋的属性
globalModulePaths:{Array} 规定不想参与css模块化的路径
css模块化 -vite配置文件中css配置流程(preprocessorOptions)
配置css预处理器的全局参数(以less为例)
命令行:lessc index.module.less [...全局参数](vite会替我们自动执行这条语句,如果需要)
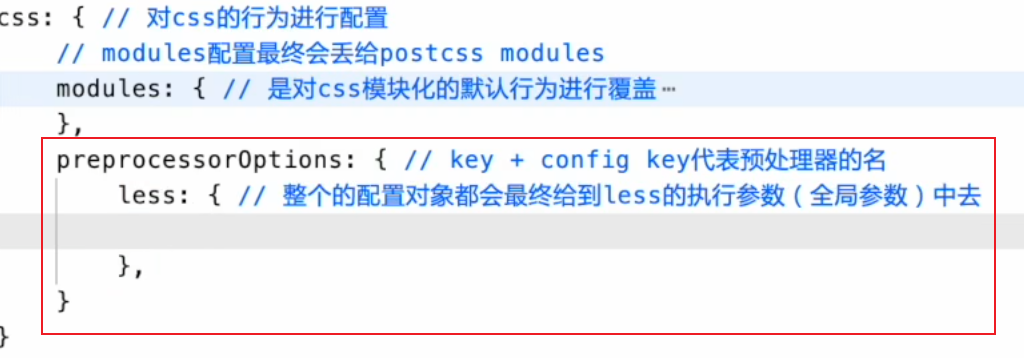
math:”always“ 计算 less 文件内的带括号的数学运算,不带括号的运算则忽略
globalVars:定义全局变量(类似于 TailwindCSS 配置文件中的定制)
css模块化 -vite配置文件中css配置流程(devSourceMap)
SourceMap:文件之间的索引
假设我们的源代码经过了编译打包,当执行这个打包后的js文件时,若有一些代码执行时报错,那么将不会在在打包后的js文件中提示错误信息,而是根据 SourceMap 索引到源项目代码文件中去查找报错地点
默认为false。当开启时,会查找到 返回浏览器端的代码 在 源项目文件的出处
POSTCSS的前世今生
(由于浏览器兼容性问题)
postcss 保证css万无一失的执行
类似与 babel,对js进行降级,保证js万无一失的执行
实际开发流程:开发者写css(怎么爽怎么写) ---> postcss ---> 返回浏览器执行
postcss:将css语法(嵌套语法、函数、变量)经预处理器编译为普通css ---> 将高级的css语法进行降级 ---> ...... ---> 前缀补全
(?)postcss为什么没有编译css全局变量:postcss是一个一个文件进行编译,vite是按需加载,那么当postcss编译过程中,遇到全局变量后,那这个全局变量只生效于那一次按需加载中的它所在的css文件中,在其他同时加载的css文件中没有被用到,相当于没有保存,那么可通过配置文件,告诉postcss不要忘记。

若要使用postcss,需要有一个配置文件通过插件来定制化这些预处理、降级、补全....的功能
小故事:其实之前postcss是内置了less、sass这些预处理器的工作的,但是由于社区不同,每次less、sass更新后,postcss则需要重新维护与之适配的插件,由于开发、维护成本太高,所以就分家了(哈哈维护当然是由社区内完成,并不是官方去干)。那这样的话,postcss只能拿预处理器编译的结果去进行后续操作,所以postcss也被业内称为“后处理器”

css模块化 -vite配置文件中css配置流程(postcss)
plugins:[ postcss-preset-env()---(预设)]
【原理篇】path.resolve以及node模块化原理简单理解
小补足:之前一直好奇像less这样的预处理器、vue/react或者上述所讲的postcss怎么解析处理自己写的源文件呢?原来他们都是利用了node的 fs 模块去读取文件内容,拿到内容之后,实际上就是拿到了很长的字符串,所谓解析就是根据各自的特性功能去进行字符串替换或一些其他的操作。
路径拼接规则:node端写文件路径时常用path.resolve + __dirname去生成绝对路径,这是不会出问题的。那如果使用相对路径的话,由于该相对路径会和当前node执行路径 process.cwd( ) 进行拼接,所以读取文件的路径可能会出错误,导致node找不到此文件。
像__dirname这种变量并没有提前声明,node如何知道得?
(这就涉及到了 node模块化 和 commonJS规范原理)

vite对静态资源的处理以及别名配置
vite 对静态资源(图片、视频、json、svg....)等基本上是开箱即用
import moduleObject from "xxxxx.png/json/mp4..." 涉及到 tree shaking 优化
默认支持 moduleObject 就代表了所加载的静态资源(会自动解析)
例如,有些构建工具,会将json解析为字符串而不是json格式
但是导出 moduleObject 这种对象的形式,不利于tree shaking优化,他不敢(也没有这样做)将对象内的属性、方法进行删减。所以一般选择按需加载的方式 import { object, function } from "..." 用哪个就引入哪个,避免无用的代码。导致项目臃肿(控制导入优化)
vite如何加载静态图片资源
import imgUrl from "......./xxx.png?url" 默认导入的结果就是该图片的url,无论加不加 "?url"
import imgData from "......./xxx.svg?raw" 读取图片的 buffer(二进制字符串),读取了svg的 二进制数据,即<svg>...</svg>后,可以直接返回给客户端,直接找地方插入<svg>,再进行后续操作

vite配置路径别名

vite配置 - resolve.alias原理(别名替换为真实路径的过程模拟)

vite配置文件对静态资源在生产环境中的影响(build)
打包后的资源文件名中为什么要有一个哈希值?
文件名中的哈希值是根据文件的内容来确定的,如果文件没变动,那么最终生成的哈希值不变,即文件名不变。
由于服务器的缓存机制,只要静态资源名字不变,他就会尝试直接使用缓存。

vite插件
vite会在生命周期的不同阶段中去调用不同插件以达到不同目的
vite内置了非常多的核心插件
vite插件 - vite-aliases
vite-aliases:通过检测当前目录下的所有文件夹,帮助我们自动生成别名
vite插件 - vite-aliases【原理篇】
vite插件是一个函数,必须返回一个对象。函数可以传参,让用户自定义一些功能,增加了灵活性
使用vite构建过程中的 config 声明周期,使用 fs 和 path 模块去读取目录下所有文件,读取后进行分类,哪个是文件,那个是文件夹
然后生成alias对象(键值对为别名:绝对路径),同样这也需要用到 fs 和 path 模块
最后进行返回 resolve 字段的 alias 配置(vite在执行过程中会将 vite.config.js 的配置对象和其他 config 进行合并,生成出最终的配置对象)

vite插件 - vite-plugin-mock
vite-plugin-mock:模拟数据(此插件依赖项为mockjs),即当后端接口尚未开发完成时,前端需要模拟请求过程,那么配置好此插件后,该插件会在前端发送请求时进行拦截,然后对返回数据进行mock(模拟)
mockjs:模拟海量数据的库
import { viteMockServe } from vite-plugin-mock 插件会在项目根目录下寻找mock文件夹,然后根据 index.js 所导出的请求模拟对象进行(请求拦截/数据模拟)
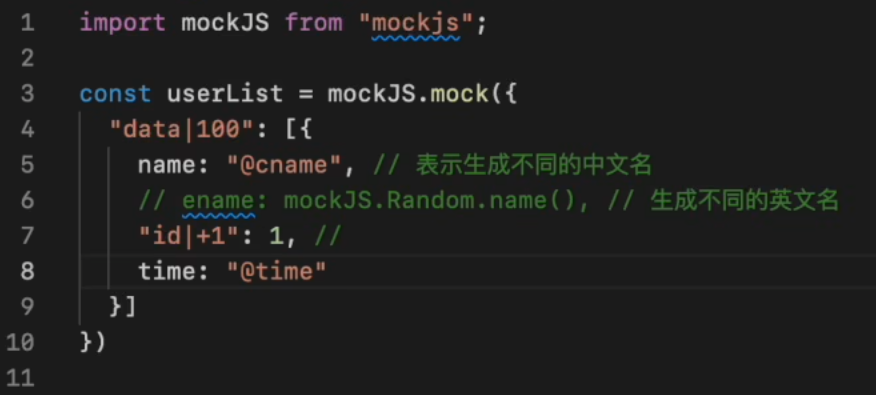
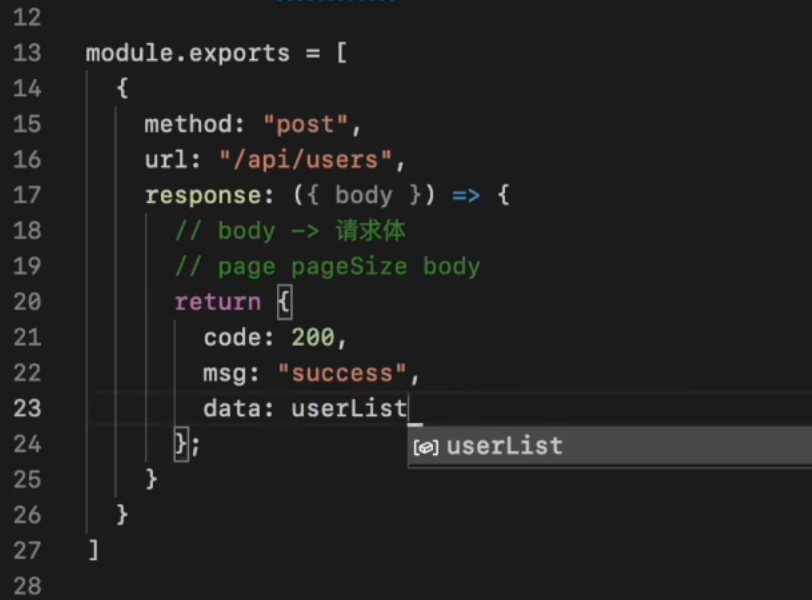
vite插件 - vite-plugin-mock【原理篇】

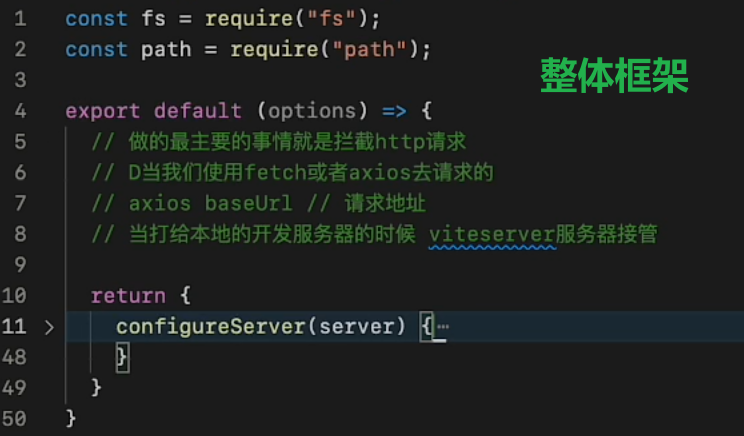

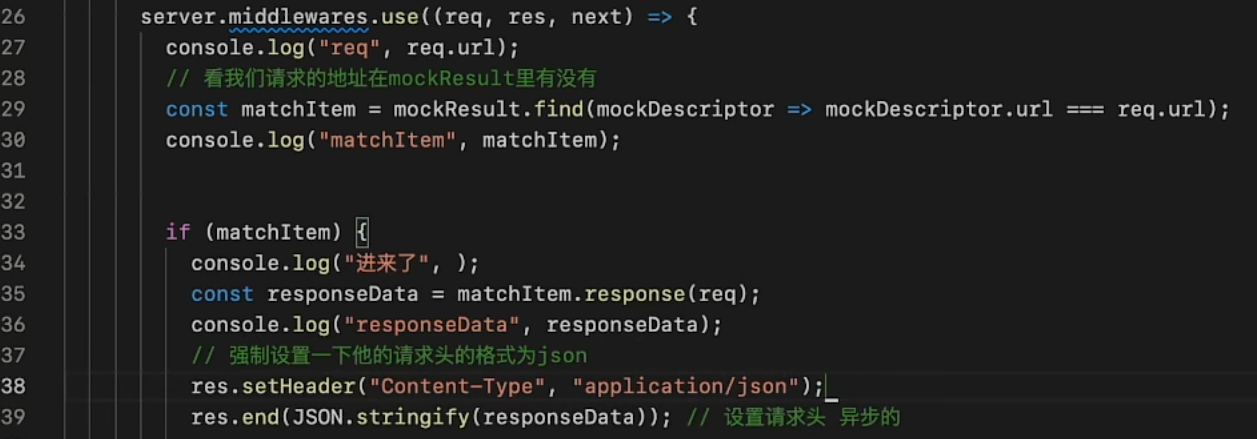
vite插件 - 总结/原理窥探
在开发中,Vite 开发服务器会创建一个插件容器来调用 Rollup 构建钩子,与 Rollup 如出一辙(vite会在开发阶段执行通用和独有的生命周期,但是打包阶段会全权交给 Rollup)
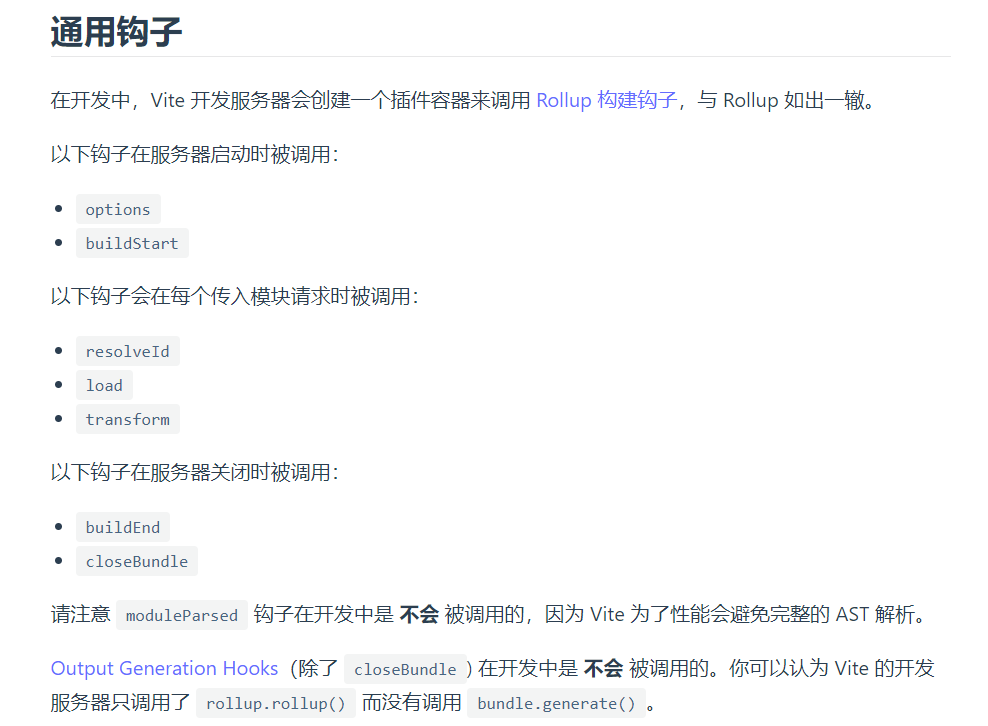
vite独有的钩子:config(在解析 Vite 配置前调用)、configServer(注册中间件,拦截请求)、transformIndexHtml(转换 index.html 的专用钩子)、configResolved(在解析 Vite 配置后调用,读取和存储最终解析的配置)
Vite与TS
TS 是一个类型检查工具,检查代码中可能会存在的隐形问题,同时给到语法提示(强类型锁定)
在企业级项目中,ts是如何去配置,如何去约束别人?
开发环境:使用vite插件 vite-plugin-checker,让ts的错误直接输出到浏览器端控制台
tsconfig.json:配置 ts检查规则
生产环境:打包ts编写的项目时,若不满足类型检查,则不会打包,即不会生成dist文件夹
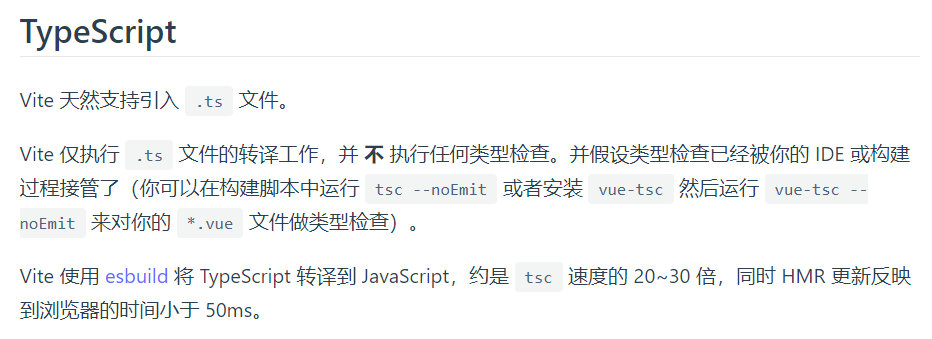
由于vite只执行转译(ts -> js),需要自己手动进行类型检查:

Vite 性能优化
优化体积:压缩、tree shaking、图片资源压缩(超过一定大小打成文件,否则转为base64插入到代码中)、cdn加载、分包...
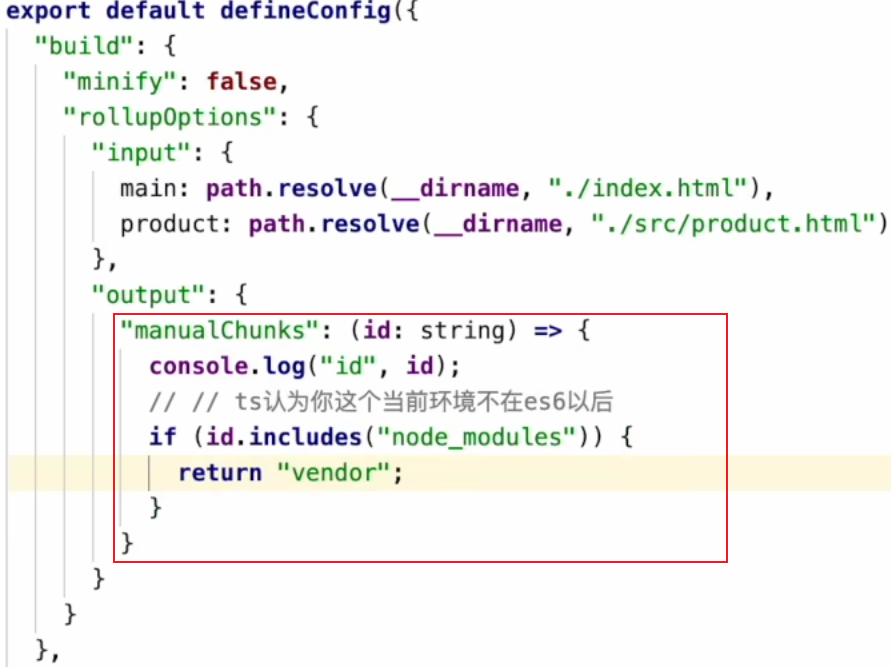
分包策略
分包:将变与不变(的代码)分隔开(源码和第三方依赖/不常更新文件),将不变单独打包
(由于浏览器缓存策略,当资源的文件名不变时,则使用缓存,文件名不一样则需要重新请求)
打包过程中进行分包,在 vite.config.js 中配置:
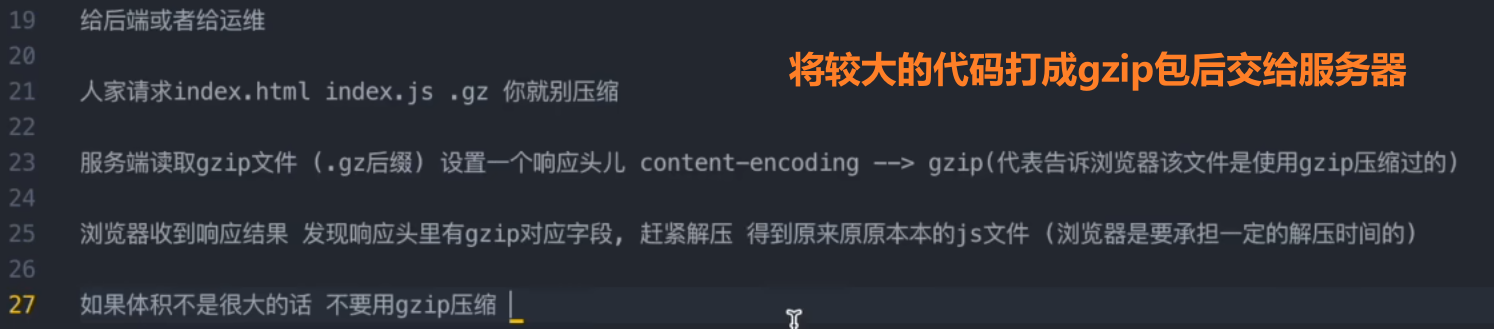
gzip压缩
vite-plugin-compression 默认有一个压缩标准,超过就压缩
动态导入
动态导入 import( "..." ).then( (...) => {...} ) 会造成打包后代码分割
原理:放到 webpack 章节分析

CDN加速
vite-plugin-cdn-import
cdn:内容分发网络
可以将项目里的依赖(第三方模块)变成cdn的形式引入,减小代码体积,因为自己项目的依赖代码可通过cdn网络加载进来(如vue、vue-lodash、lodash...),打包后可以不在自己代码中

·
Vite 跨域 - 前后端解决方案(server.proxy)
前端解决方案
时期:开发阶段
目的:测试接口
问题:跨域
解决:一般使用 ---构建工具或者脚手架或者第三方库的proxy--- 代理配置
以vite举例解决跨域。配置好vite字段后,访问 ’/api' 时,访问路径首先由浏览器所在地址 + ’/api' 拼接而成,进行请求
再交由vite,检查是否有 ’/api' 的跨域代理策略,若有,则按照配置进行再次请求(由vite开发服务器进行请求,没有跨域问题)

后端解决方案
Ngnix:代理服务(服务器之间的请求 不 存在跨域)
配置身份标记:Access-Control-Allow-Origin 字段